The common data consistency errors that can occur are:
- 2601 Cannot insert duplicate key row in object '%.*ls' with unique index '%.*ls'
- 20598 The row was not found at the Subscriber when applying the replicated command.
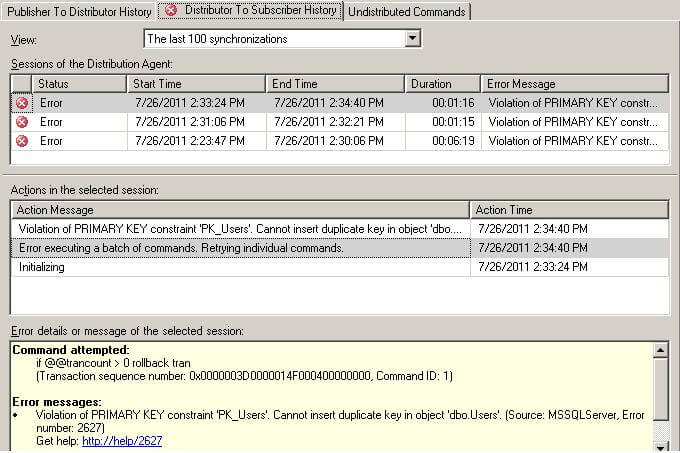
- 2627 Violation of PRIMARY KEY constraint 'PK__A'. Cannot insert duplicate key in object 'dbo.A'.
Since real-time data replication is synchronous, it is an all-or-none proposition, meaning that in order to guarantee transactional consistency and atomicity, what ever transactions are committed to the publisher, must be committed to the subscriber. For example, a write operation (INSERT, UPDATE, DELETE) either completes on both sides or not at all. These are not considered complete until acknowledgement from the subscriber. Therefore, when there is a data consistency error, and the replication engine cannot guarantee consistency - the distribution agent stops.
Here is a typical violation of a Primary Key constraint error as shown by Replication Monitor:
Ultimately, you must investigate further as to the cause of these consistency errors, and fix the problem. However, there are some options that can allow Replication to continue while you find out the root cause which we will cover in this tip.
Solution
By default, when the Distribution Agent encounters any of the above-mentioned errors, the agent stops. However, there are some workarounds, that will prevent these consistency errors from interfering with replication and let it continue running. SQL Server will log these errors, which is very important, so you can come back to them, understand what the error condition is, why it is occurring, and resolve the issue.
There are some caveats of course, and it is recommended to use the workaround cautiously, as it is better to know why the error occurred or why the specific transaction needs to be skipped rather than resolved. We'll talk about some of these scenarios later on.
Skipping These Errors
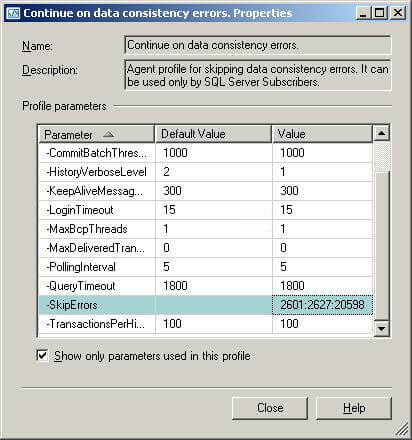
To have Replication "ignore" these errors, Microsoft provides us with a set of predefined replication agent files, that are installed on the Distributor. The one we are discussing is the Distribution Agent Profile, which defines parameters in the profiles for the Distribution Agent. Here we can find the -SkipErrors parameter that will skip errors 2601, 2627, and 20598 as described above.
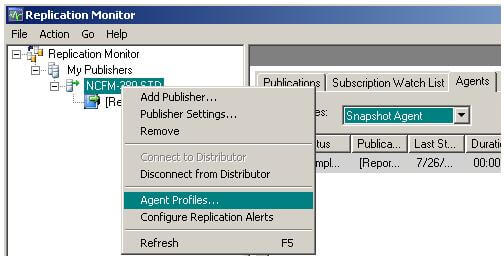
To change the default profile that the Distributor is using, you can access the Agent Profiles dialog box from Replication Monitor.
Once Replication Monitor is launched, you'll then need to drill-down to the publisher under "My Publishers", select the appropriate Publication, right-click and select "Agent Profiles" as shown here:
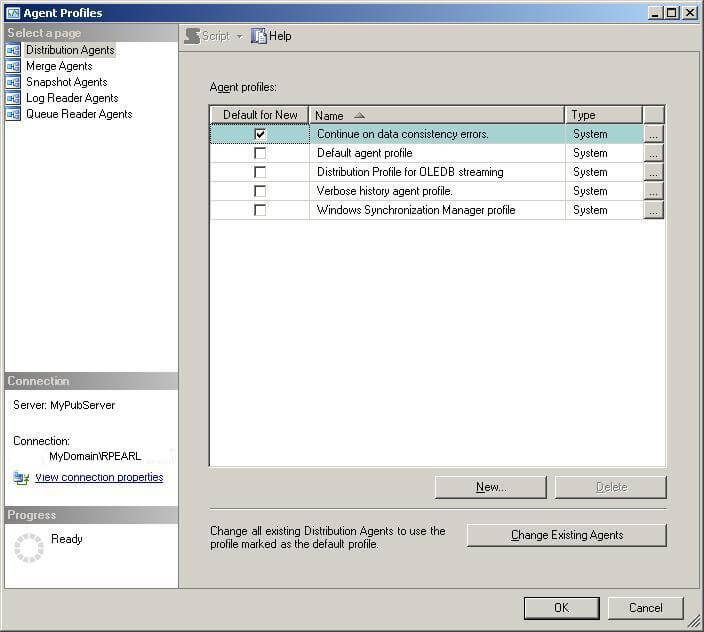
When the Agent Profiles window is displayed, make sure the "Distribution Agents" page is selected. Then in the Agent profiles section, click and select the "Default for New" checkbox for "Continue on data consistency errors".
You can click on the ellipsis button next to this profile, to view its parameters. The properties dialog box will open, and if you scroll down a bit, you will see the -SkipErrors Parameter, as highlighted below:
Finally, click , and then to set the new default profile for the Distribution Agent.
Enabling the Profile Changes
Before the new profile takes affect, you MUST restart the Distribution Agent. There are two ways to do this. I think this confuses most people, because there are various replication agents, but none specifically say "Distribution Agent".
- You can drill-down in SSMS to your Replication Folder --> Local Subscriptions
- Select your subscriber, and right click "View Synchronization Status" You will see the START/STOP buttons. This is your distribution agent.
- Click . A message will prompt you, "Are you sure you want to stop synchronizing? Data that has already been synchronized will not be rolled back"
- Click .
- Once the agent is stopped, then click to start synchronizing again.
To restart the distribution agent in T-SQL, you can run the following commands from a SQL Query Window, and must provide the specified parameter info:
-- To STOP the Distribution Agent:
sp_MSstopdistribution_agent @publisher, @publisher_db, @publication, @subscriber, @subscriber_db
--To START the Distribution Agent:
sp_MSstartdistribution_agent @publisher, @publisher_db, @publication, @subscriber, @subscriber_db
The Continue on Data Consistency Errors profile is now active.
Reasons Why Consistency Errors Occur in Replication
Now that we have told Replication to "skip" these errors, and carry on, this band-aid approach still needs to be looked at more closely. We need to answer, why are these errors occurring? Here are some of the reasons why:
- Your subscriber should be "read-only". In other words, the only thing that should be writing to your Subscriber, is the Publisher. You need to check if you are doing ad-hoc updates, inserts, deletes of your own. (Applies to 1-way transactional replication)
- Check to see if you have any triggers enabled at the subscriber. If triggers are fired, there could be INSERTS, UPDATES and DELETES putting duplicate rows in a table(s).
- Check if you are replicating identity columns which can cause "duplicate key" errors, and primary key collisions.
- Deferred Updates - UPDATE Statements May be Replicated as DELETE/INSERT Pairs - can cause constraint errors.
- Make sure the publisher and subscriber are in-sync - Run Validations, or any data compare tool between the two databases.
You can view the logged consistency errors by executing the following query against the distribution database:
Use Distribution
go
select * from dbo.MSrepl_errors
where error_code in ('2601','2627','25098')
Important information to help troubleshoot, such as the time, error details, and the xact_seqno, resides in this table. You will see similar output to this: